

You all know of Radarr as one of the top tools for social listening, monitoring and analytics. But what makes us stand out is our technology and in this blog, we’re sharing some behind the scenes information about the NLP engine of Radarr that brings the insights you derive from our dashboard.
Radarr leverages powerful Natural Language Processing (NLP) algorithms to uncover quick and actionable insights from billions of online conversations. The NLP Engine can process data in more than 140 languages, specializing in Asian Languages like Indonesian, Chinese, Japanese, Vietnamese, Thai, etc apart from English and provide analytics on a micro per-post level and a macro level.
There are two parts to this article – The first part walks you through some steps that are key to Radarr’s NLP Engine in transforming unstructured and messy data into a structured, machine understandable format by using some data preprocessing techniques.

Steps to organizing your data in the NLP engine
Step 1: Language identification
The first and most important step is Language Identification – to automatically detect the language(s) present in each conversation and in the queries built using the Query Engine.
Radarr uses an ensemble of models and techniques to infer the language of a text.
Language models built using a train dataset that contains a mix of social media and formal language data provides the basis for our language detection.
In cases of short form text, where it is a challenge to predict the language, we resort to statistical approaches based on the language-specific vocabularies that we have built in-house over time.
In cases where the language has still not been identified, we use the country and locale to give us hints about the language.

Once the language has been identified, the data stream is distributed into multiple preprocessing pipelines for groups of languages.
This step is essential as certain groups of languages have their own unique vocabulary, tokenization methodology and direction of writing among other differences.
For example languages like Japanese and Chinese do not have spaces between their words and languages like Arabic and Urdu are written from right to left.
Step 2: Tokenization
The next step is to break down streams of text into words, terms, sentences, or other meaningful elements called tokens. The Tokenization step has a very important effect on the rest of the pipeline as they form the basis of chunking the text into meaningful pieces for further lexical analysis.
The simplest form of tokenization is the white space tokenization which is used to split words based on just a white space (which is useful for latin languages). Radarr uses multiple models pre-trained on social data across industries in order to learn the vocabulary per language to tokenize text meaningfully.

Step 3: Normalization
Once the posts have been segmented into meaningful tokens, they are converted into their normalized form.
Normalization is the process of converting tokens to their base standard format in order to make semantic comparison easier across conversations. An ensemble of methods is used for normalizing words like Lemmatization and Stemming.
Step 4: Vectorization
Finally, before we glean insights from these billions of conversations, we convert all the text data into a machine understandable, vector format or Embeddings in order to perform advanced NLP techniques such as making word/sentence predictions, finding word/sentence similarities and understanding text semantics. This step of Vectorization or representation of text forms the foundation for all of Radarr’s Advanced NLP models.
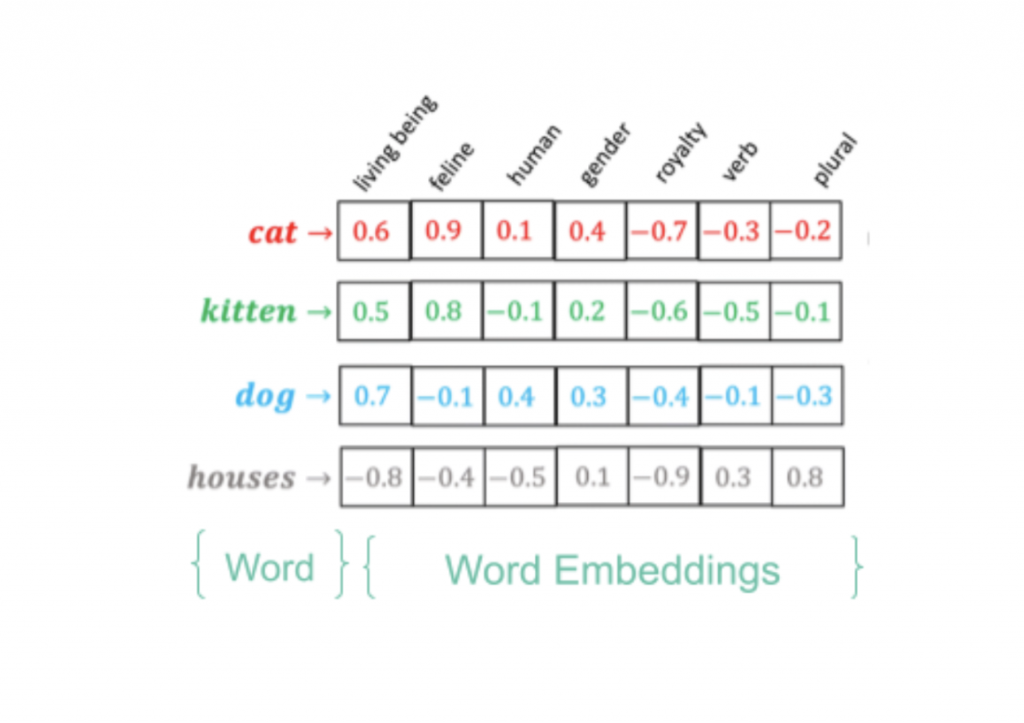
So when it comes to being able to listen to and monitor online conversations in multiple languages, our NLP engine is one of the most robust out there.
But that’s not all about it.
In Part 2 of this article, we will explain about the insights that we extract using some Advanced NLP techniques after the initial data preprocessing.
To be notified, don’t forget to subscribe to our blog or try Radarr.










